There is a serious problem with how people attempt to explain why they enjoy certain music. Listeners don’t have the tools, or capacity, to accurately respond to questions like “What kind of music do you listen to?” or “Who are your favorite bands?”.
Most people are isolated within small social and geographic circles and the scale at which we miss out on good music is astronomical. There’s endless opportunity to discover new music that we might love, and endless opportunity to share what we find and bring joy to others. Almost every music streaming or purchasing platform these days has a recommendation engine, but none has ways to keep track of our thoughts about the music so we can figure out what we like and what we don’t like. In fact, it seems most people don’t have any systematic way to form relationships between musical entities. Over the last couple months, I’ve endeavored to create a solution, and this article presents a web-based application I built to enable deeper reasoning about the music I enjoy.
When I first began thinking of this problem, I wanted a way to methodically record my emotional and perceptual experiences with music so that I could have a better idea of what I like, what I don’t like, and how to respond to a question like “What’s your favorite album of all time?” This matters to me because I love music and believe that the music I listen to plays an integral part in building my personality and defining who I am. Enjoying a wide-variety of music allows me to always have a fallback conversation point (although, it doesn’t work when people don’t have a strong connection to music), and I’ve found that people love talking about their tastes in music. You can learn a lot about a person by the musical qualities they enjoy.
The problem is: how can you quantify the way you think and feel toward music? Ultimately, I’d like to be able to authentically and accurately answer: What are your top 3 albums? and perhaps, Who are your favorite musicians? Knowing my favorite genres would also be exciting. How, then, do we quantify, or at least document, our reactions to records?
These questions are based upon the assumption that there’s a linear rank that albums could be lined up on. Humans are obsessed with ranking: sports teams ranked on ESPN, product reviews ranked on Amazon, universities rankings on US News. Rankings are intuitive, simple, and natural, therefore they show up prominently in this project. The question then becomes, How do we rank something subjective and aesthetic, like music?
The study of aesthetics has a long history, and volumes of philosophical arguments and perspectives. Immanuel Kant was one of the most invested spokespeople of aesthetics, arguing that aesthetic judgement is rooted in neither scientific knowledge nor is it bound by rules of understanding. It is the thoughts surrounding individual objects, within and around themselves alone, and in the light of the sensory experiences they generate. He argues that aesthetic judgement cannot be supported by objective or universal principles, for a judgment of taste is always individual.
With that in mind, it makes sense then to forget about making a multi-user platform: everyone has a different idea of what’s best, and the music charts already exist as an attempt to aggregate reviews over many people. Instead, we need a per-individual solution.
A way to organize the collection of music I’ve invested time into is important, both for record keeping (to refresh my limited memory when needed) and for using to rank music. Thus, I developed a system to log my music collection with all the features I need to informatively rank albums. Based upon lots of comparisons between albums, we can construct a ranking, and thus begin to answer the questions we care about.
I sought to build my own platform to handle my specific needs: the needs of the individual. I began by throwing together a prototype in Python, using the command line as an interface. I tested out the idea of having an input/output pipeline for making comparisons between albums on a variety of characteristics. This helped me identify viable algorithms and create a feedback loop with my study of aesthetics to refine how I could compare albums, ultimately converging upon the idea of pairwise comparisons amongst a variety of incisive questions. The results are two-fold: I have a distributed, cognitive tool which guides my memories and thoughts on records, and I also have a way to quantitatively assess aesthetic pieces to definitively answer the questions I was first motivated by.
Music Collection
I love talking about music. But when you begin to span dozens of genres, decades, styles, and more, you start to lose track of what’s what and who’s who. To help support my memory, and make it easy to jot notes (which is proven to help you remember things), my application has multiple fields for writing. Each album can receive a review, as can each track. Ideally, after listening to each track and giving them reviews, you’d have a good idea for the global structure and feel of the album.
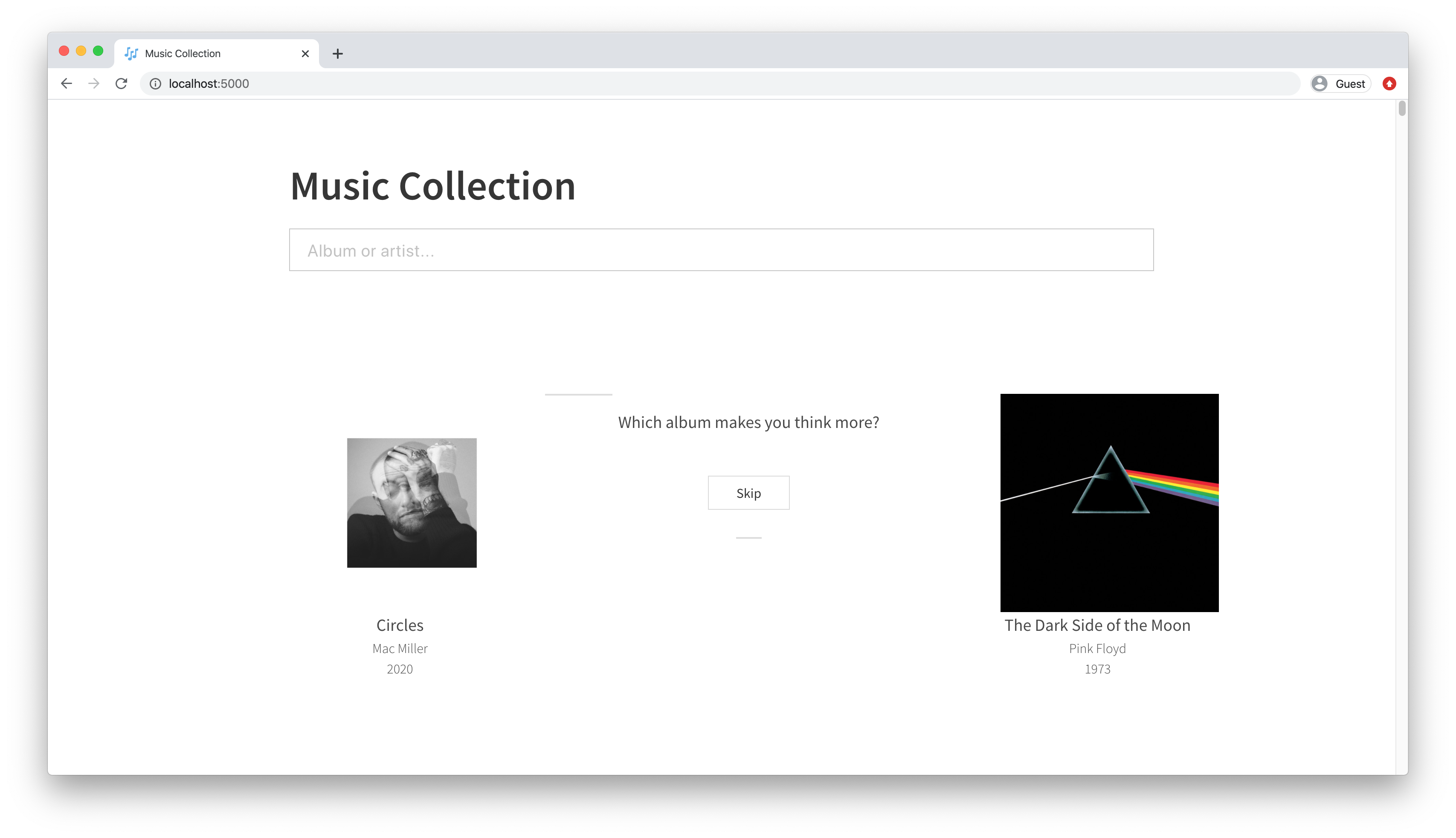
To ensure I could draw upon a vast database of world music, I integrate with Spotify, my primary platform for listening to music. This works well, because any record I find or listen to on Spotify can be loaded into the application. The search bar at the top provides a portal to access Spotify’s collections:
Below the search, there’s an area which allows two albums to be compared. Which albums get chosen for comparison is optimal (see below), so I can be sure that each comparison is doing the most to generate an accurate ranking. The comparison happens according to a series of questions which I created, although even these are subjective and individualistic: what I think makes a great album isn’t necessarily what you think does (although I tried to be a generalist).
Development
I underwent the task of teaching myself the React-Redux ecosystem from scratch to make this happen. I would consider myself a JavaScript bystander – occasionally using it with decent proficiency – but learning React and Redux required me to (re)learn a lot. I would argue there’s a decently steep learning curve to the frameworks, given the way the application data are held quite separately in an immutable state. Nonetheless, I made it happen and experienced only a few bouts of hair ripping.
It was all a learning experience, but from the start I had a rough idea of the size and scope of my application. I intended to apply some React-Redux best practices, which occasionally required some major refactoring, but it was probably worth it. The application is modularized, and I’ve tried to ensure the hierarchy of components keeps logic and data at the appropriate scope. One downside of my current configuration is that the application store holds a lot of data, especially the album collection data. This has started to become a little cumbersome on reloads, especially as I begin to notice small performance hits. I’ve searched for articles outlining best practices for scaling applications with React but haven’t come across anything suitable yet.
For storage, I created a MongoDB instance served locally. To interface with this, my backend API is built with Flask, which also routes the main page. This Flask API is responsible for all album data manipulation, including ranking albums and serving category scores, caching and serving album art, and storing changes to reviews and listening history. I also utilize the Spotify Developer’s API to fetch information about albums, including tracklists and album art. Upon adding a new album to my collection, the album art is cached locally on my computer to prevent me from making an unnecessarily large number of requests to Spotify’s image CDN.
In summary, the application architecture is as follows:
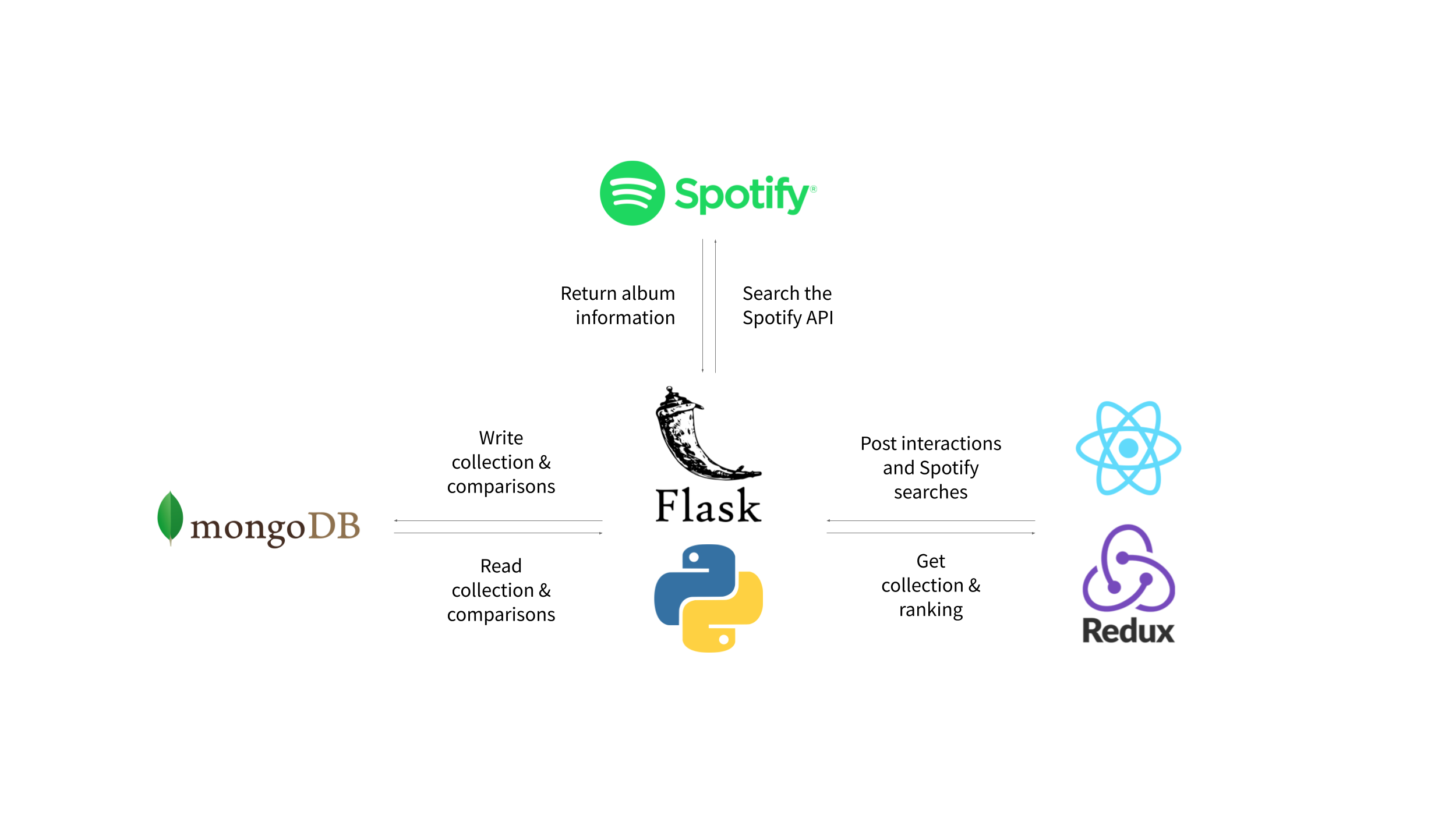
Some details are left out here, but the gist is conveyed. I toyed with the idea of using a relational database instead of NoSQL MongoDB, but figured the rest of my code would be most interpretable with a NoSQL framework. Since I’m not pushing the edges of storage capabilities, I didn’t anticipate this to create any noticeable performance issues either.
At the top of the application, there are methods for filtering and sorting. As my collection grows larger, it’s become increasingly important for me to be able to quickly find albums. I’ve noticed this as I talk about music and want to pull up an album quickly, and when I’m rating albums, and need a refresher. I have five ways to sort: 1) by the date I added the record to my collection, 2) by the date I last listened to the record, 3) by the record’s runtime, 4) by the record’s rank, and 5) by the record’s recommendation score. I can also search according to artist or album name, or by genre:
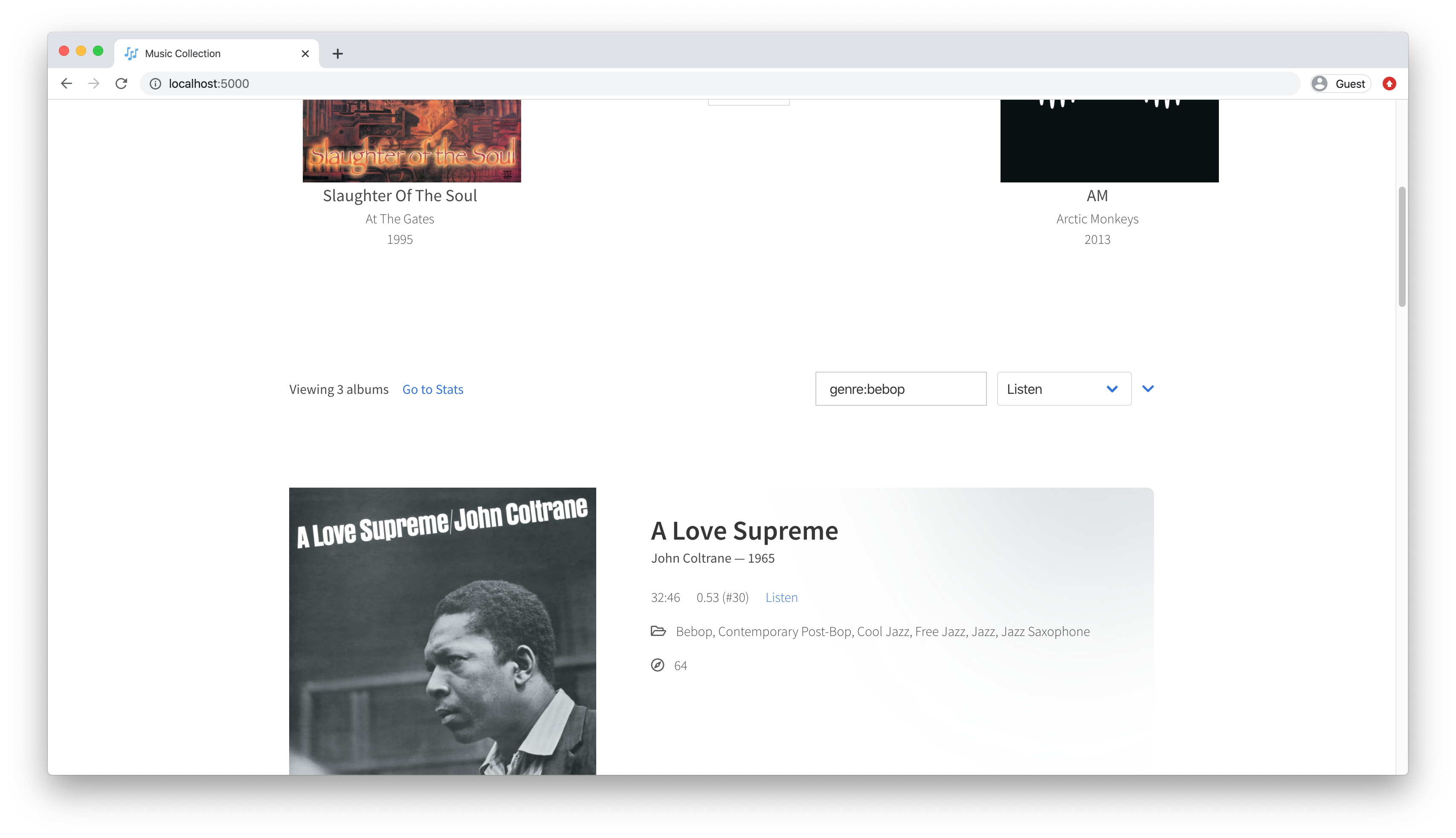
Below I discuss more about the album ranks and recommendation scores. The genres are a somewhat quasi-genres: they’re actually genres of the artist. Spotify doesn’t yet allow developers to access album genres, so I make due with broader genres. Usually, artists have genres; however, some music I’ve discovered is highly esoteric and therefore without classification. This was an edge case I didn’t anticipate but luckily doesn’t affect the UX too much.
Design
At heart, I’m a sucker for elegant and compelling design. This includes color schemes, negative space, typography, the whole thing. As a result, a constant voice inside me begged for better and better user interface design. I acquiesced.
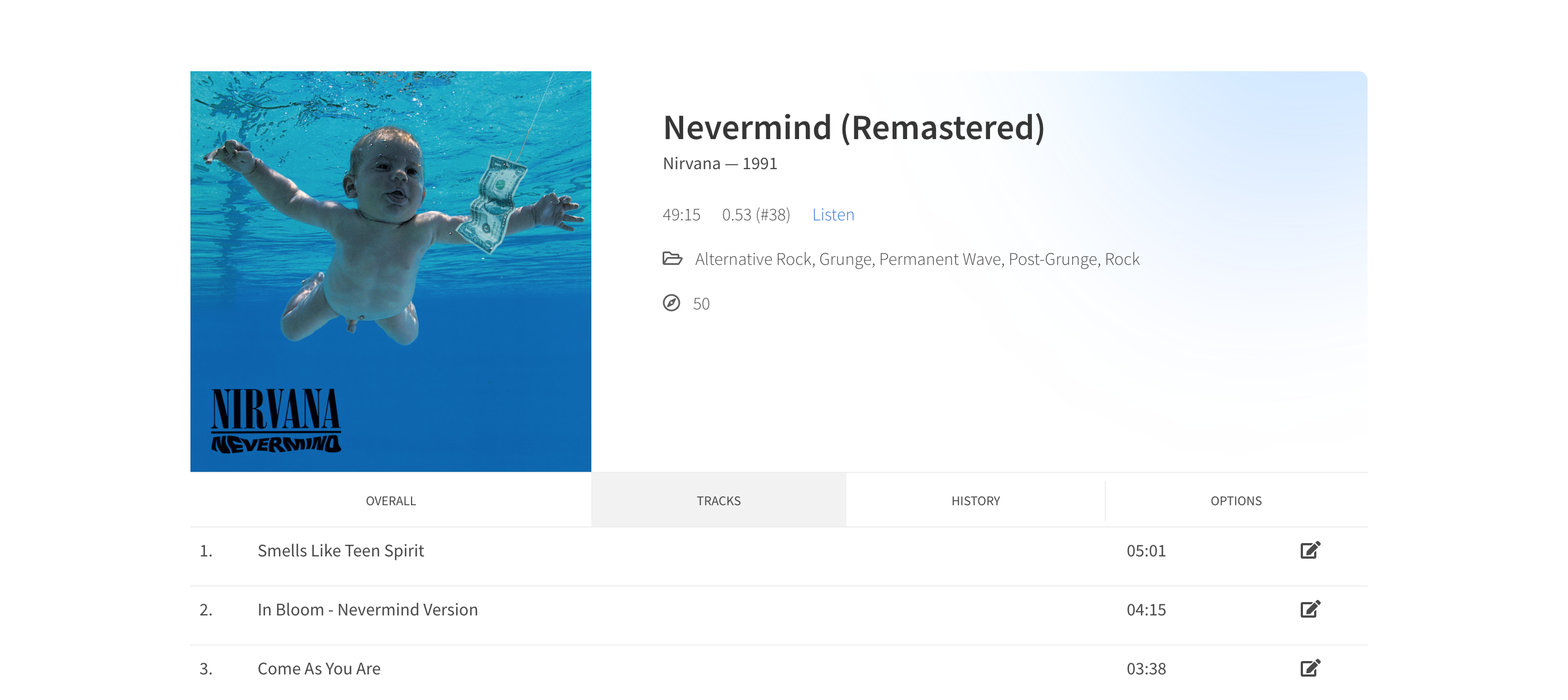
The design stemmed from some ideas I had and styles I liked, as well as a combination of inspirations from Apple Music, Spotify, various projects I discovered on Behance, and input from friends. It amounted to a clean, straightforward design, with ample incorporation of the uniqueness and beauty inherent in many album artworks. I wanted plenty of negative space to let the application breathe, even if that meant having a long, long list of albums. Simplicity was in mind from the graphs to the fonts.
With some CSS blur, rotate, and saturation filters, I took the artwork for each record and placed it in the top right corner of each card, creating album themes unique to each record and gently bringing in a little more color and pop.
The icons come from FontAwesome.com, which conveniently can be tied together with specialized React components to ensure proper updates and loading. More can be read here on that.
Scoring and Ranking
What really piqued my interest in the beginning was the idea of scoring or ranking albums, on some “best” to “worst” subjective scale. I started out by researching what experts considered characteristics of the “best” music. I found quite a few academic papers. I read hours of album reviews from strangers on internet forums. I took notes while watching music reviewers on YouTube. And I considered my own personal taste. Some researchers have attempted the idea of quantitatively judging aesthetics, but nothing’s seemed to have gained recognition or suit my needs. All my research led to the conclusion that there probably wasn’t a good way to rank music (or art in general), let alone quantify its relative superiority to other works.
But it wouldn’t be fun if we just ended the project here. So, I abstracted out 12 categories which I think help explain what makes a good record. Each category became associated with a question, or prompt, for which someone could say one album or the other answered the question better. For example, I think the album art contributes a non-negligible amount to how good an album is. Some of the best albums ever have intriguing, provocative, relevant, and/or memorable artwork (see Dark Side of the Moon, Nevermind, etc.). Here is the list of questions which albums may be compared under:
- Which album art contributes to the album more?
- Which album would you buy for a music critic?
- Which has songs that build an album greater than its parts?
- Which album makes you think more?
- Which album better balances soft and loud?
- More songs on which album didn’t flow well with the rest?
- Which album would you buy for your best friend?
- Which are you more likely to get distracted during while listening?
- Which would you choose if forced to listen to one once every day?
- Taking only the lyrics from these albums, which would make a better story in book form?
- Which album has more filler tracks?
- Which album has better vocals?
Each of these questions results in a pairwise comparison, and luckily, there is a long history of ranking according to pairwise comparison. Much of the interest in this field relates to ranking sports teams, chess players, or other types of competitive activities. One popular algorithm the ELO rating method. However, we can also picture albums as competitors and apply the same principles.
Previous work by Heckel et al (2018) proposed a pairwise ranking algorithm with theoretically optimal guarantees for active learning. Their work was particularly relevant to my system because they designed their algorithm specifically for an active learning setting. This means that there are ways to figure out what the model doesn’t know, or isn’t confident in, and leverage this uncertainty to pick the next, most informative comparison. The algorithm by Heckel et al wasn’t quite what I was looking for, but Maystre & Grossglauser’s (2017) work proved valuable. They suggested optimal competitive uncertainty sampling with the popular Bradley-Terry ranking model simply by choosing to compare the pair whose relative ordering in most uncertain (has the smallest gap between scores).
The Bradley-Terry model framework is by far one of the most common approaches to ranking entities given pairwise comparisons. Using the choix Python package, I compute a Bradley-Terry model for each rating category over all albums. On output, each album is associated with a score from 0 to 1. I take all 12 scores, average them, and rank the albums using this average score. So far, this has worked quite well.
However, I have requirements for when an album can be ranked. Namely, each album is assigned default values for each category which fall between about 0.4 and 0.6, subject to some quirks in the Bradley-Terry models. Only after I’ve listened to the album three full times through may I begin to compare it to other albums. I do this a safeguard and baseline. I don’t want to misjudge an album after having only listened to it once. It may take time to understand it, and often does. Once an album reaches three listens, it will be ready to be queued up in the comparison framework.
Recommendation Algorithm
With a desire to get the most out of the music I know, I sought out a recommendation engine to suggest which album I should listen to next.
Most engineers default to complex algorithms when they think of recommendation algorithms. However, my data are fairly slim, and I had some ideas in mind to build a heuristic algorithm instead. This just means that instead of a black-box recommendation algorithm, relying on the albums content or perhaps other data about my listening behavior, I have a deterministic set of rules to create a “recommended score”.
This recommended score is based on five things: when was the last time I listened to the album, when did I add the album to my collection, how many minutes long is the album, how many times have I listened to the album (and how close is it to having 3 listens), and how common are the genres the artist is listed under. Using these attributes, scores for each are given to each album, and then a weighted average is taken to create an overall recommended score. Sort the recommended score from highest (1) to lowest (0) and there’s the recommendation. It appears on each album card to the right of a small compass icon.
Unfortunately, this doesn’t discover new music I’ve never heard before; only records I’ve put in my collection already. This isn’t the worst case scenario though. In fact, one of the things I enjoy most is crate-digging. During the COVID-19 lockdown, this now is usually digital crate digging, but I still love to put in the effort to find new artists myself. One great label I recommend for finding eclectic and esoteric music is the Numero Group.
Last Words
Overall, I use my application almost every day now as both a repository and an information source. It’s used to record my thoughts and feelings about albums and tracks, and it’s used to recommend what I should listen to next. I filter and sort and discover new patterns in what I like and don’t like. I see gaps in genres of music which I should listen to, forcing me out of my comfort zone and into artists and albums I wouldn’t normally think to explore.
I won’t be sharing my top albums or genres yet, I have lots of albums to add and listen to before that can happen.
I maintain this project on GitHub, so feel free to fork it if you think you’d also benefit from it. If you have questions, you may email me or post an issue. I’ll respond either way. One potential use for this is to go beyond music – the framework would work just as great to determine your favorite books, beers, or birds (birds? why not, I needed the alliteration).